Weighted MinHash
MinHash can be used to compress unweighted set or binary vector, and estimate the unweighted Jaccard similarity. It is possible to modify MinHash for weighted Jaccard on **multisets** by expanding each item (or dimension) by its weight (usually its count in the multiset). However this approach does not support real number weights, and doing so can be very expensive if the weights are very large. Weighted MinHash is created by Sergey Ioffe, and its performance does not depend on the weights - as long as the universe of all possible items (or dimension for vectors) is known. This makes it unsuitable for stream processing, when the knowledge of unseen items cannot be assumed.
In this library, datasketch.WeightedMinHash objects can only be created from
vectors using datasketch.WeightedMinHashGenerator, which takes the dimension as
a required parameter.
# Using default sample_size 256 and seed 1
wmg = WeightedMinHashGenerator(1000)
You can specify the number of samples (similar to number of permutation functions in MinHash) and the random seed.
wmg = WeightedMinHashGenerator(1000, sample_size=512, seed=12)
Here is a usage example.
from datasketch import WeightedMinHashGenerator
v1 = [1, 3, 4, 5, 6, 7, 8, 9, 10, 4]
v2 = [2, 4, 3, 8, 4, 7, 10, 9, 0, 0]
# WeightedMinHashGenerator requires dimension as the first argument
wmg = WeightedMinHashGenerator(len(v1))
wm1 = wmg.minhash(v1) # wm1 is of the type WeightedMinHash
wm2 = wmg.minhash(v2)
print("Estimated Jaccard is", wm1.jaccard(wm2))
It is possible to make datasketch.WeightedMinHash have a update interface
similar to MinHash and use it for stream data processing. However,
this makes the cost of update increase linearly with respect to the
weight. Thus, update is not implemented for datasketch.WeightedMinHash in
this library.
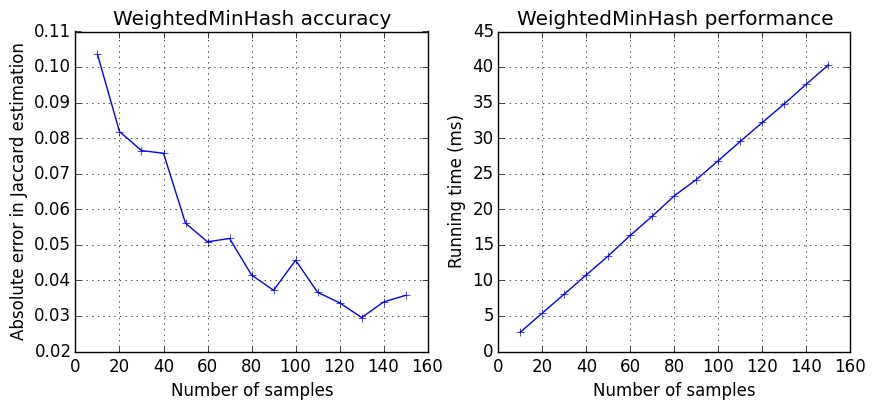
Weighted MinHash as similar accuracy and performance profiles as MinHash. As you increase the number of samples, you get better accuracy, at the expense of slower speed.
datasketch.MinHashLSH and
datasketch.MinHashLSHForest
can also be used to index datasketch.WeightedMinHash.
import numpy as np
from datasketch import WeightedMinHashGenerator
from datasketch import MinHashLSH
v1 = np.random.uniform(1, 10, 10)
v2 = np.random.uniform(1, 10, 10)
v3 = np.random.uniform(1, 10, 10)
mg = WeightedMinHashGenerator(10, 5)
m1 = mg.minhash(v1)
m2 = mg.minhash(v2)
m3 = mg.minhash(v3)
# Create weighted MinHash LSH index
lsh = MinHashLSH(threshold=0.1, sample_size=5)
lsh.insert("m2", m2)
lsh.insert("m3", m3)
result = lsh.query(m1)
print("Approximate neighbours with weighted Jaccard similarity > 0.1", result)